As large language models (LLMs) become increasingly indispensable in technology-driven enterprises, the quest to fine-tune these models for specific tasks has taken on significant importance. Two primary methodologies have emerged in this space: traditional fine-tuning and in-context learning (ICL). While fine-tuning allows models to be tailored to specialized datasets, ICL offers a fascinating approach that leverages examples within input prompts without altering the model’s internal parameters. Recent research from Google DeepMind and Stanford University sheds new light on the comparative strengths of these methods, presenting a compelling case for combining them through an innovative technique known as augmented fine-tuning.
The Mechanics of Fine-Tuning vs. In-Context Learning
Fine-tuning involves deep adjustments where a pre-trained LLM is retrained on smaller, domain-specific datasets. This allows the model to internalize new vocabularies, concepts, and tasks without completely discarding its prior knowledge. On the other hand, ICL operates without modifying the model’s core parameters; instead, it enriches the input with contextual examples, assisting the model in making sense of new queries based on previously encountered tasks.
In many scenarios, fine-tuning can be likened to crafting a tailored suit; it concedes a delightful fit for specific occasions but can be resource-intensive and time-consuming. In contrast, ICL resembles a flexible wardrobe allowing quick adaptations depending on immediate needs, although it incurs higher computational costs with each usage.
The Research Journey: A Rigorous Comparison
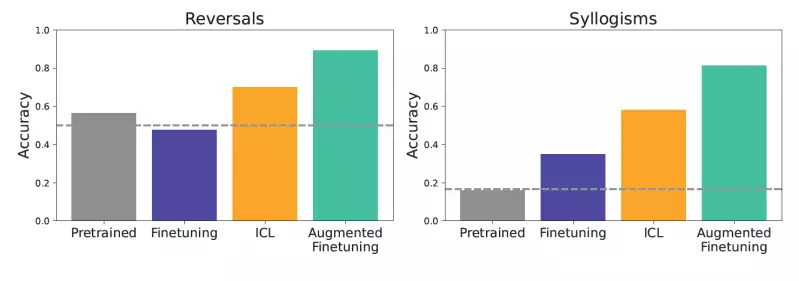
The studies conducted by Lampinen and his colleagues aimed to rigorously analyze how the two methodologies generalize when exposed to novel data. Utilizing carefully designed synthetic datasets that removed all recognizable linguistic elements, the researchers tested the models’ abilities to draw logical conclusions and respond to queries based solely on the underlying structures. Through this experimental setup, they could ensure that the evaluations were as fair and accurate as possible.
The outcomes revealed a striking efficiency in ICL regarding generalization capabilities compared to conventional fine-tuning methods. For example, when tasked with inferring logical reversals or conclusions—a testament to the models’ reasoning abilities—ICL-equipped models frequently outperformed their fine-tuned counterparts. Such findings challenge the status quo, suggesting that ICL could be the key to a stronger understanding of complex relationships within data.
Augmented Fine-Tuning: The Best of Both Worlds
Recognizing the individual strengths of both methodologies, the researchers proposed an augmented fine-tuning strategy, marrying the adaptive advantages of ICL with the stable foundation of fine-tuning. This innovative approach envisages generating supplementary training examples through ICL, thereby enriching the dataset used for fine-tuning.
Two strategies emerged within this concept: the local and the global approach. The local approach generated inferential examples based on singular pieces of information, enhancing fine-tuning data by rephrasing existing sentences. In contrast, the global strategy provided the entire dataset context to encourage the LLM to produce richer inferences, resulting in deeper insights and robust understanding.
When applied to fine-tuning, these augmented datasets exhibited a marked improvement in generalization performance, significantly surpassing both standard fine-tuning and ICL on its own. This shift signals a groundbreaking direction for enterprises aiming to enhance their LLM applications’ reliability through finely-tuned models.
The Practical Implications for Enterprises
For developers, the introduction of augmented fine-tuning leads to a pivotal reconsideration of model customization strategies. While it may increase initial costs due to additional ICL steps, the strategy proves to be economically beneficial over time, especially when the enhanced generalization potential translates into better accuracy and performance in real-world applications.
One illustrative scenario presented by Lampinen points to company documents that may require nuanced interpretations. For entities relying heavily on specific internal knowledge, the dual approach of ICL and augmented fine-tuning equips models with robust reasoning capabilities—greatly amplifying their potential to engage with complex queries.
Future Directions in LLM Customization
The pioneering work by Lampinen and his team highlights a fertile ground for future explorations in LLM customization. Although the research denotes distinct advantages in adopting augmented fine-tuning, caution is warranted. Each firm’s unique requirements and datasets will invariably influence the efficacy of the chosen customization path.
As researchers continue to unearth insights into the learning mechanisms of foundation models, the work’s ultimate goal endorses a nuanced understanding of optimization for downstream applications. With pressing needs for reliable LLM capabilities surging in diverse industries, embracing innovations like augmented fine-tuning could potentially redefine and elevate the landscape of artificial intelligence.